Values of the Reconciliation: Row by Row Comparison TestStep
The tables below contain a description of the Row by Row Comparison TestStepValues.
An X in the Optional column indicates that the respective value is optional and not mandatory for your TestStep.
Database data sources

|
Use either Connection, or DSN, or Connection String to connect to the source and target of your data. |
|
Value |
Description |
Optional |
|---|---|---|
|
Connection |
Use this ModuleAttribute if you want to use one of the connections you have defined in the Connection Manager. The Connection ModuleAttribute replaces the ModuleAttributes DSN, UserID, Password, and ConnectionString. To specify which connection you want to use in your test, click into the Value field and select a connection from the drop-down menu. Note that you can't override the specified connection with dynamic expressions, such as buffers or test configuration parameters. |
X |
|
DSN |
Specify the data source you want to use for your comparison. Enter the Data Source Name specified in the ODBC Data Source Administrator. After a connection is established, this is also used as ConnectionName. |
X |
|
UserID |
User of the database which you want to use. |
X |
|
Password |
Password of the user. |
X |
|
Connection String |
Uses the defined connection string instead of the DSN, UserID, and Password ModuleAttributes. |
X |
|
SQL Statement |
Any SQL statement. |
|
|
Options - Connection Timeout |
Time in seconds after which Tosca aborts an active connection. |
X |
|
Options - Command Timeout |
Time in seconds after which Tosca aborts an active command. |
X |
|
Options - Byte Array Handling |
Defines which encoding Tosca should use if the data type is a byte array. |
X |
WebHDFS data sources
|
Value |
Description |
Optional |
|---|---|---|
|
Base URL |
Must contain protocol, address, and port number of the Hadoop cluster where the file you want to use is stored. |
|
|
Filename |
Full path to the file on the Hadoop cluster. A leading slash character / is mandatory. For example: /demo/data/Customer/DWH_Extract_Hadoop.txt |
|
|
Authentication Type |
Select one of the following authentication types:
For a detailed description of these authentication types, see chapter "Kerberos authentication for Web Hadoop File Systems". |
|
|
UserID |
User used to connect to WebHDFS. |
|
|
Password |
Password of the user. |
|
|
Options - Column Separator |
Specify the separator, if columns are delimited with a separator. |
|
|
Options - Row Separator |
Character which delimits a row. The default value is \r\n. |
X |
|
Options - Encoding |
Specifies the file encoding format. Allowed values include Default, ASCII, Unicode, UTF32, and UTF8. The Default format uses the encoding of your operating system. |
X |
|
Options - Buffer Size |
Number of bytes the read buffer uses when fetching data. This should be greater than the number of bytes in each row. The default value is 1024. |
X |
File data sources
|
Value |
Description |
Optional |
|---|---|---|
|
Filename |
Full file path and file name. |
|
|
Options - Column Separator |
Specify the separator, if columns are delimited with a separator. |
|
|
Options - Row Separator |
Character which delimits a row. The default value is \r\n. |
X |
|
Options - Skip Lines Starting With |
Rows which start with the specified values are excluded from tests. To define more than one value, enter a semicolon-separated list. |
X |
|
Options - Encoding |
Specifies the file encoding format. Allowed values include Default, ASCII, Unicode, UTF32, and UTF8. The Default format uses the encoding of your operating system. |
X |
SSH data sources
|
Value |
Description |
Optional |
|---|---|---|
|
Hostname |
Name of the host to which you want to connect. By default, port 22 is used. |
|
|
Filename |
Full file path and file name. For example: /demo/data/Customer/DWH_Extract_Hadoop.txt |
|
|
UserID |
User used to connect via SSH. |
|
|
Password |
Password of the user. |
|
|
Options - Column Separator |
Specify the separator, if columns are delimited with a separator. |
|
|
Options - Row Separator |
Character which delimits a row. The default value is \r\n. |
X |
|
Options - Encoding |
Specifies the file encoding format. Allowed values include Default, ASCII, Unicode, UTF32, and UTF8. The Default format uses the encoding of your operating system. |
X |
|
Options - Buffer Size |
Number of bytes the read buffer uses when fetching data. This should be greater than the number of bytes in each row. The default value is 1024. |
X |
|
Options - Skip Lines Starting With |
Rows which start with the specified values are excluded from tests. To define more than one value, enter a semicolon-separated list. |
X |
OLAP data sources
|
Value |
Description |
Optional |
|---|---|---|
|
SSAS |
Connect to SQL Server Analysis Services. |
|
|
SSAS - Connection string |
Connection string for SSAS. |
|
|
SSAS - Query |
Query to retrieve data to compare. |
|
|
Options - Connect Timeout |
Time in seconds after which Tosca BI aborts an active connection. The default value is 30 seconds. |
X |
|
Options - Command Timeout |
Time in seconds after which Tosca BI aborts an active command. The default value is 180 seconds. |
X |
Row Options
|
Value |
Description |
Optional |
|---|---|---|
|
Skip first #n rows |
Define the number of rows which should be ignored. Skipping starts at the top of the data source. |
X |
Column Options
|
Value |
Description |
Optional |
|---|---|---|
|
1st Row Contains Column Names |
Specifies whether the first line of the data source contains the column names. The default value is True. |
X |
|
Remap Column Names - Current Name |
Remap the column names. The value in the Name column represents the column to rename, the value in the Value column represents the new name. |
X |
|
Tricentis Tosca uses this locale to determine the format of the numeric values, mainly decimal and thousand separators, of the columns that are defined in Tolerances. |
X |
Cell Settings
Cell settings contains two options:
-
All Columns - Option applies one of the actions below to all columns.
-
Single Columns - <Name> applies one of the actions below to a specified column. To specify a column, replace <Name> with the column name.
|
Value |
Description |
|---|---|
|
Trim |
Removes all leading and trailing white space characters. Default scope: HeaderAndData |
|
Trim[<character>] |
Removes all leading and trailing occurrences of the specified character. Default scope: HeaderAndData Exchange <character> with the character you want to remove. To remove a ", enter the " four times, e.g. Trim[""""]. |
|
TrimStart |
Removes all leading white space characters. Default scope: HeaderAndData |
|
TrimStart[<character>] |
Removes all leading occurrences of the specified character. Default scope: HeaderAndData Exchange <character> with the character you want to remove. To remove a ", enter the " four times, e.g. TrimStart[""""]. |
|
TrimEnd |
Removes all trailing white-space characters. Default scope: HeaderAndData |
|
TrimEnd[<character>] |
Removes all trailing occurrences of the specified character. Default scope: HeaderAndData Exchange <character> with the character you want to remove. To remove a ", enter the " four times, e.g. TrimEnd[""""]. |
|
Replace[<string>][<string>] |
Replaces all occurrences of the first string with the second string. Default scope: Data |
|
Substring[<start index>] |
Extracts a part of a longer string. The extract starts at the defined start index position and runs until the end of the string. Default scope: Data For example: Substring[9] with input Project Manager returns Manager. |
|
Substring[<start index>][<length>] |
Extracts a part of a longer string. The extract starts at the defined start index position and contains the number of characters specified in length. Default scope: Data For example: Substring[9][3] with input Project Manager returns Man. |
|
Right[<length>] |
Extracts a part of a longer string. The extract runs from the end of the string towards the beginning and contains the number of characters specified in length. Default scope: Data For example: Right[7] with input Project Manager returns Manager. |
|
Lowercase |
Converts the string to lowercase using the currently active locale. Default scope: Data For example: Lowercase with input Project Manager returns project manager. |
|
Lowercase[Culture:<culture name>] |
Converts the string to all lowercase. Lowercase[Culture:<culture name>] uses the given culture name to create a new locale. Default scope: Data For example: Lowercase[Culture:zh-Hans] uses the culture information of "Chinese(simplified)" to convert uppercase to lowercase characters. |
|
Uppercase |
Converts the string to uppercase using the currently active locale. Default scope: Data For example: Uppercase with input Project Manager returns PROJECT MANAGER. |
|
Uppercase[Culture:<culture name>] |
Converts the string to all uppercase. Uppercase[Culture:<culture name>] uses the given culture name to create a new locale. Default scope: Data For example: Lowercase[Culture:en-us] uses the culture information of "English - United States" to convert lowercase to uppercase characters. |
|
Trim double quotes |
Removes leading and trailing double quotes. For example: Trim double quotes with input """Project Manager""" returns Project Manager. |
To change the default scope of an action, add a Scope parameter:
-
To apply the action to the header row only, add the parameter [Scope:Header].
-
To apply the action to all data rows but not the header, add the parameter [Scope:Data].
-
To apply the action to the header and all data rows, add the parameter [Scope:HeaderAndData].

|
This example illustrates how to replace all instances of the string CustomerDataAustria with the string CustomerDataUSA. Apply this change to the header and all data rows. To do so, define the following action: Replace[<CustomerDataAustria>][<CustomerDataUSA>][Scope:HeaderAndData] |
General Options
The General Options TestStepValues offer the following options besides error reporting:
|
Value |
Description |
Optional |
|---|---|---|
|
Columns to Exclude |
Semicolon-separated list of columns to exclude from comparison. |
X |
|
Case Sensitive Column Names |
If set to True, column matching from source to target is case-sensitive. For example: ID is not the same as id. |
X |
|
Matched Data Log Filename |
Enter the full file path to a CSV file into which you want to log matched data. Logging matched data impacts the speed of row by row comparisons. Tricentis recommends that you use local paths instead of slower network paths. |
X |
|
Tolerances |
Define tolerances to avoid a mismatch in case of a slight difference between source and target value. Use positive and negative numeric values or percentages. If you use two values to create a tolerance range, separate them by semi-colon. Example value: -5;+5 |
X |
Additional TestStepValues
In addition to the TestStepValues of the source and target system, Reconciliation tests also offer the following TestStepValues:
|
Value |
Description |
|---|---|
|
Row Key |
Defines the required primary key for the row. To use more than one column, define a semicolon-separated list. |
|
Result |
Allows you to verify the outcome of the comparison. If the comparison succeeds, the value is OK. |
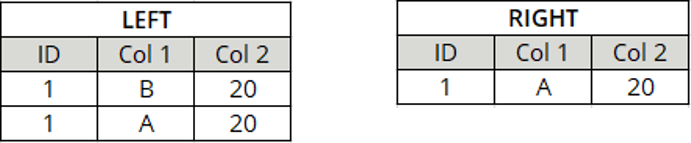
RowKeys identify a row uniquely. They usually consist of one or more columns.
To define your RowKey, follow the steps below:
-
Select the Complete Row by Row Comparison TestStep.
-
In the ValueRange of the Input RowKey, enter the name of the column that uniquely identifies a row.
-
To use more than one column, enter several column names separated by a semicolon.
-
To use all columns, type All Source Columns.
-
|
The column name specified in the RowKey must be exactly the same name as in the table. This includes upper case, lower case, and blank spaces. |

Row Key with two columns as identifiers


Results allow you to verify the outcome of the comparison. To verify the result, follow the steps below:
-
Select the Complete Row by Row Comparison TestStep.
-
In the Value column of Result, enter the expected result:
-
To verify against a successful comparison, enter the value OK.
-
To verify against an expected result, use the result text from the Loginfo once you have executed your TestCase and customize it.
-

Verify Result