Configure a Kafka connection
You can configure an Apache Kafka connection in the API Connection Manager.
This allows you to connect to a Kafka topic which stores messages that are sent by one or more publishers and read by one or more consumers. For detailed information on Kafka, see the Apache Kafka documentation.
Configure your connection
To configure a Kafka connection, follow the steps below:
-
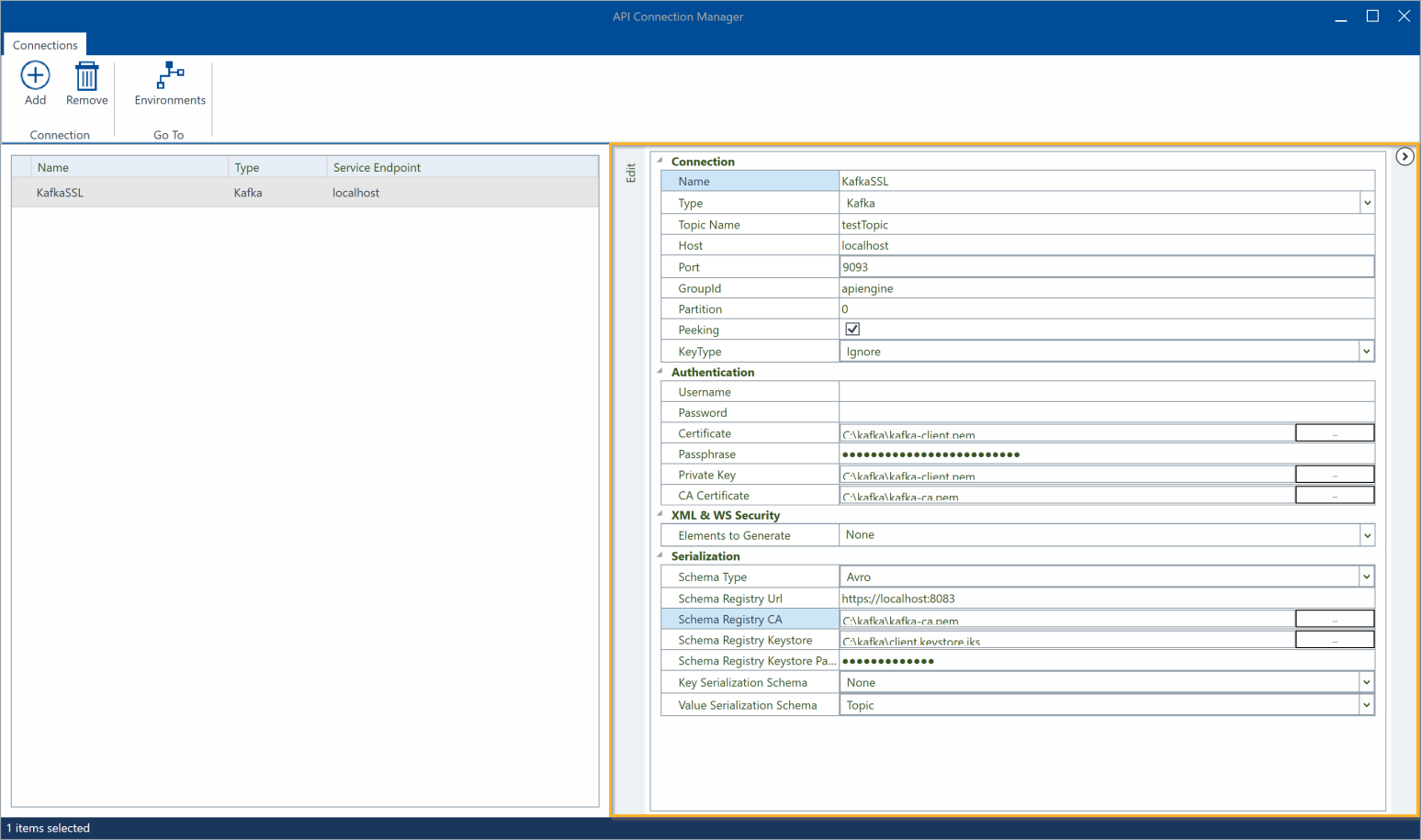
Go to the Edit section.
-
Specify a Name for your connection.
-
From the Type drop-down menu, select Kafka.
-
Enter the name of the Topic you want to connect to.
-
Specify the Host. This is the name or IP address of the Kafka server host.
-
Enter the Port to listen to.
-
Specify the GroupId of the consumer group. This is the name of the group of consumers that subscribed to this topic.
-
Enter the number of the Partition that stores the records (messages).
Kafka topics are split into multiple partitions which allows for a distribution of large amounts of data on one or more servers. Each partition has a number such as 0 or 5.
-
Enable Peeking to retrieve records from a partition without committing.
This allows you to read any record, regardless of its position in the partition and without influencing the offset. The offset, which defines the position of a record, indicates which records have already been consumed and which unread record the API Engine should pull next.
-
Specify the message KeyType with one of the following options:
-
Ignore to set the message to null and serialize only the value, but not the key.
-
None to exclude from serialization both, value and key.
-
Integer message.
-
String message.
-
-
If your connection requires authentication, you have two options: authenticate with Username and Password or via SSL. If you choose SSL, populate the following fields instead:
-
Specify your Certificate file in .pem.
-
Insert your Passphrase. This is the passphrase for your private key.
-
In Private Key, specify the path to your private key in .pem.
-
Specify the CA Certificate in .pem. This is the root CA Certificate for verifying the Kafka broker's certificate.
-
-
Optionally, configure XML and web service security.
-
Optionally, add Avro schema-based serialization for Kafka messages to define the data schema for a record's value. This schema describes the fields allowed in the value, along with their data types. For detailed information on Avro schema, see the Apache Avro documentation.

API Engine 3.0 doesn't support the default value for array types in an Avro schema. For detailed information, see the example on this page.
From the Schema Type drop-down menu, select Avro and add a Schema Registry Url and a Schema that defines the data structure in a JSON format.
If the Schema Registry requires SSL, fill out the following fields:
-
Specify the Schema Registry CA. This is the directory path to the CA Certificate.
-
In Schema Keystore Registry, specify the path to the keystore you have used for authentication.
-
In Schema Keystore Registry Password, enter the keystore password.
-
-
Configure the Value Serialization Schema and Key Serialization Schema:
-
None to serialize the key or the value.
-
Topic to serialize the key or the value by using the registered schema for the topic.
-
Configure a Kafka connection
You can now use your Kafka connection for testing. For detailed information on how to run Kafka topics, see chapter "Run Kafka messages".
Avro schema serialization format support
Kafka connection support the following schemas:
-
Array
-
Boolean
-
Double
-
Enum
-
Float
-
Int
-
Logical: Date, Time (millisecond), Time (microsecond), Timestamp (millisecond), Timestamp (microsecond), Local timestamp (millisecond), Local timestamp (microsecond), UUID
-
Long
-
Null
-
Record
-
String
-
Union
The default value "default": [ ] for array types "type": "array" in an Avro schema isn't supported.
{
"default": [],
"type": "array",
"items": {
"type": "record",
"name": "Attribute",
"fields": [
...
]
}
}