Values of the Reconciliation: Row by Row Comparison TestStep
A reconciliation test gives you an in-depth comparison between two data sets. It compares each individual source row to each target row. While aggregated tests are faster, reconciliation tests are very precise. However, depending on the size of your data sets, the comparison may be time and resource consuming.
This topic lists all Row by Row Comparison TestStepValues that you need to create your reconciliation test.
Define your source and target
Fill out the Source and Target TestStepValues to connect to your data source and target. You can choose between the following data types:
To use a database as your source or target, fill out the following TestStepValues:
|
Value |
Description |
Optional |
|---|---|---|
|
Connection |
Use this ModuleAttribute if you want to use one of the connections you have defined in the Connection Manager. The Connection ModuleAttribute replaces the ModuleAttributes DSN, UserID, Password, and ConnectionString. To specify which connection you want to use in your test, click into the Value field and select a connection from the drop-down menu. Note that you can't override the specified connection with dynamic expressions, such as buffers or test configuration parameters. |
X |
|
DSN |
Specify the data source you want to use for your comparison. Enter the Data Source Name specified in the ODBC Data Source Administrator. After a connection is established, this is also used as ConnectionName. |
X |
|
UserID |
User of the database which you want to use. |
X |
|
Password |
Password of the user. |
X |
|
Connection String |
Uses the defined connection string instead of the DSN, UserID, and Password ModuleAttributes. |
X |
|
SQL Statement |
Any SQL statement. |
|
|
Options - Connection Timeout |
Time in seconds after which Tosca aborts an active connection. |
X |
|
Options - Command Timeout |
Time in seconds after which Tosca aborts an active command. |
X |
|
Options - Byte Array Handling |
Defines which encoding Tosca should use if the data type is a byte array. |
X |
To use a file as your source or target, fill out the following TestStepValues:
Data Integrity supports Avro files as source or target.
Limitations
Working with Avro files has the following limitations:
-
Supported compression codecs are GZIP, Snappy, and 'none'.
-
Avro maps aren't supported.
-
Skipping rows isn't supported.
-
Data Integrity supports only one level of nesting for the result of a JSONPath. Deeper nested objects and arrays are stringified. To express access to deeper nested objects, use a separate JSONPath.
-
Data Integrity doesn't support cartesian products, which is when two JSONPaths return values from two different arrays.
Work with JSONPaths
JSONPaths allow you to transform a hierarchical Avro file into a tabular format. The Reconciliation Module only supports tabular comparisons.
To determine and test JSONPaths, Tricentis recommends to first convert the Avro file into a JSON representation. To do so, you can use an online tool like Avro to JSON converter. Secondly, use the JSON output in a JSONPath tester like JSONPath Online Evaluator.
You can create a file with JSONPaths to select specific column names and transformation logic from your Avro file. This helps flatten the file.

|
In this example, you use a file with JSONPaths to select column names from an Avro file. First, you use an Avro file reader to convert the content of your file to JSON format: To select columns names, you create a file that contains JSONPaths in the following format: Copy
The row-by-row comparison can now read the file in the following way: |
Choose one of the following Avro file types:
|
Value |
Description |
Optional |
|---|---|---|
|
Path |
Full path to an Avro file or a folder that contains multiple Avro files with the same schema. You can use wildcards *. If you use a folder or wildcard, Data Integrity orders the files by name and reads them first to last. Examples: C:\MyAvroFolder\Sample.avro C:\MyAvroFolder C:\MyAvroFolder\Samples*.avro |
|
|
JSONPaths Filename |
Full path to a file with JSONPaths. This allows Tosca to select column names and transformation logic. The JSONPaths file must be in the same bucket/directory as the data files or in a sub-bucket/directory. If the file is in a sub-bucket/directory, enter the relative path together with the file name. If you leave this value empty, Data Integrity uses a wildcard * as JSONPath. It unpacks hierarchical structures one level deep. Sample content for JSONPath: For Name, note the following:
|
x |
|
Value |
Description |
Optional |
|---|---|---|
|
Access Key Id |
S3 access key ID. |
|
|
Bucket Name |
Name of the bucket that contains the file. If you store the file in a sub-folder, enter the path in the following format: <bucket name>/<sub-folder>. Example: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Full name of your source/target file. Use wildcards * to specify multiple files. |
|
|
Provider Name |
Name of your S3 provider. You can enter one of the following values:
|
|
|
Region |
The physical region where the file is stored. Examples: us-east-1: US Region, Northern Virginia, or Pacific Northwest eu-central-1 : EU (Frankfurt) Region ap-southeast-2: Asia Pacific (Sydney) Region |
|
|
Secret Access Key |
Secret access key. If you want to access the file anonymously, leave the value blank. |
x |
|
JSONPaths Filename |
Full path to a file with JSONPaths. This allows Tosca to select column names and transformation logic. The JSONPaths file must be in the same bucket/directory as the data files or in a sub-bucket/directory. If the file is in a sub-bucket/directory, enter the relative path together with the file name. If you leave this value empty, Data Integrity uses a wildcard * as JSONPath. It unpacks hierarchical structures one level deep. Sample content for JSONPath: For Name, note the following:
|
x |
|
Value |
Description |
Optional |
|---|---|---|
|
Service Account Filepath |
Path to the JSON file that contains the service account credentials. |
|
|
Project Id |
Globally unique identifier of the project you want to access. |
|
|
Region |
The physical region where the file is stored. Examples: us-east-1: US Region, Northern Virginia, or Pacific Northwest eu-central-1 : EU (Frankfurt) Region ap-southeast-2: Asia Pacific (Sydney) Region |
|
|
Bucket Name |
Name of the bucket that contains the file. If you store the file in a sub-folder, enter the path in the following format: <bucket name>/<sub-folder>. Example: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name of your source or target file and its relative path from the bucket root. |
|
|
JSONPaths Filename |
Full path to a file with JSONPaths. This allows Tosca to select column names and transformation logic. The JSONPaths file must be in the same bucket/directory as the data files or in a sub-bucket/directory. If the file is in a sub-bucket/directory, enter the relative path together with the file name. If you leave this value empty, Data Integrity uses a wildcard * as JSONPath. It unpacks hierarchical structures one level deep. Sample content for JSONPath: For Name, note the following:
|
x |
|
Value |
Description |
Optional |
|---|---|---|
|
Account |
Storage account name. |
|
|
Key |
Storage account key. |
|
|
SAS Url |
Account-level SAS URL or container level SAS URL. If you use Account and Key instead, leave this value blank. Example: https://blobname.blob.core.windows.net/?sv=2020-08-04&ss=bfqt&srt=sco&sp=rwdlacupitfx&se=2023-12-10T16:46:02Z&st=2021-12-10T08:46:02Z&spr=https&sig=XXXX |
x |
|
Bucket Name |
Name of the bucket that contains the file. If you store the file in a sub-folder, enter the path in the following format: <bucket name>/<sub-folder>. Example: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name of your source or target file and its relative path from the bucket root. |
|
|
JSONPaths Filename |
Full path to a file with JSONPaths. This allows Tosca to select column names and transformation logic. The JSONPaths file must be in the same bucket/directory as the data files or in a sub-bucket/directory. If the file is in a sub-bucket/directory, enter the relative path together with the file name. If you leave this value empty, Data Integrity uses a wildcard * as JSONPath. It unpacks hierarchical structures one level deep. Sample content for JSONPath: For Name, note the following:
|
x |
If you want to integrate a different Cloud Service Provider on your Windows or Linux machine, you need to create your own rclone configuration. To do so, run the corresponding executable file:
-
rclone_x64_windows.exe config on Windows.
-
rclone_x64_linux config on Linux.
By default, when you install the Data Integrity Agent on Windows, this file is located at c:\Program Files\TRICENTIS\Tricentis Tosca Data Integrity Agent\Agent.
|
Value |
Description |
Optional |
|---|---|---|
|
Configuration Filename |
Name of the local rclone configuration file. |
|
|
Remote Name |
Name of the configuration section from the configuration file. |
|
|
Bucket Name |
Name of the bucket that contains the file. If you store the file in a sub-folder, enter the path in the following format: <bucket name>/<sub-folder>. Example: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name of your source or target file. |
|
|
JSONPaths Filename |
Full path to a file with JSONPaths. This allows Tosca to select column names and transformation logic. The JSONPaths file must be in the same bucket/directory as the data files or in a sub-bucket/directory. If the file is in a sub-bucket/directory, enter the relative path together with the file name. If you leave this value empty, Data Integrity uses a wildcard* as JSONPath. It unpacks hierarchical structures one level deep. Sample content for JSONPath: For Name, note the following:
|
x |
For more information about how to configure rclone, click here.

|
When you work with CSV files, use the format recommended in RFC 4180. This ensures that Data Integrity can handle the files properly. |
Choose one of the following CSV file types:
|
Value |
Description |
Optional |
|---|---|---|
|
Filename |
Full file path and file name of your source or target file. |
|
|
Options - Column Separator |
Character that delimits columns, if you use a column deliminator in your tables. |
|
|
Options - Row Separator |
Character that delimits a row. The default value is \r\n. |
|
|
Options - Skip Lines Starting With |
Character that excludes rows from the test. Tosca excludes any row that starts with this charater. You can define multiple characters; to do so, enter a semicolon-separated list. |
|
|
Options - Encoding |
File encoding format. Enter Default, ASCII, Unicode, or UTF8. If you enter Default, Tosca uses the encoding of your operating system. |
|
|
Value |
Description |
Optional |
|---|---|---|
|
Hostname |
Name of the host to which you want to connect. By default, port 22 is used. |
|
|
Filename |
Full file path and file name. For example: /demo/data/Customer/DWH_Extract_Hadoop.txt |
|
|
UserID |
User used to connect via SSH. |
|
|
Password |
Password of the user. |
|
|
Options - Column Separator |
Specify the separator, if columns are delimited with a separator. |
|
|
Options - Row Separator |
Character which delimits a row. The default value is \r\n. |
X |
|
Options - Encoding |
Specifies the file encoding format. Allowed values include Default, ASCII, Unicode, UTF32, and UTF8. The Default format uses the encoding of your operating system. |
X |
|
Options - Buffer Size |
Number of bytes the read buffer uses when fetching data. This should be greater than the number of bytes in each row. The default value is 1024. |
X |
|
Options - Skip Lines Starting With |
Rows which start with the specified values are excluded from tests. To define more than one value, enter a semicolon-separated list. |
X |
|
Value |
Description |
Optional |
|---|---|---|
|
Access Key Id |
S3 access key ID. |
|
|
Bucket Name |
Name of the bucket that contains the file. If you store the file in a sub-folder, enter the path in the following format: <bucket name>/<sub-folder>. Example: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Full name of your source/target file. Use wildcards * to specify multiple files. |
|
|
Provider Name |
Name of your S3 provider. You can enter one of the following values:
|
|
|
Region |
The physical region where the file is stored. Examples: us-east-1: US Region, Northern Virginia, or Pacific Northwest eu-central-1 : EU (Frankfurt) Region ap-southeast-2: Asia Pacific (Sydney) Region |
|
|
Secret Access Key |
Secret access key. If you want to access the file anonymously, leave the value blank. |
x |
|
Options - Column Separator |
Character that delimits columns, if you use a column deliminator in your tables. |
x |
|
Options - Row Separator |
Character that delimits a row. The default value is \r\n. |
x |
|
Options - Skip Lines Starting With |
Rows which start with the specified value are excluded from tests. To define more than one value, enter a semicolon-separated list. |
x |
|
Options - Encoding |
File encoding format. Allowed values are Default, ASCII, Unicode, and UTF8. The Default format uses the encoding of your operating system. |
x |
|
Value |
Description |
Optional |
|---|---|---|
|
Service Account Filepath |
Path to the JSON file that contains the service account credentials. |
|
|
Project Id |
Globally unique identifier of the project you want to access. |
|
|
Region |
The physical region where the file is stored. Examples: us-east-1: US Region, Northern Virginia, or Pacific Northwest eu-central-1 : EU (Frankfurt) Region ap-southeast-2: Asia Pacific (Sydney) Region |
|
|
Bucket Name |
Name of the bucket that contains the file. If you store the file in a sub-folder, enter the path in the following format: <bucket name>/<sub-folder>. Example: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name of your source or target file and its relative path from the bucket root. |
|
|
Options - Column Separator |
Character that delimits columns, if you use a column deliminator in your tables. |
x |
|
Options - Row Separator |
Character that delimits a row. The default value is \r\n. |
x |
|
Options - Skip Lines Starting With |
Rows which start with the specified value are excluded from tests. To define more than one value, enter a semicolon-separated list. |
x |
|
Options - Encoding |
File encoding format. Allowed values are Default, ASCII, Unicode, and UTF8. The Default format uses the encoding of your operating system. |
x |
|
Value |
Description |
Optional |
|---|---|---|
|
Account |
Storage account name. |
|
|
Key |
Storage account key. |
|
|
SAS Url |
Account-level SAS URL or container level SAS URL. If you use Account and Key instead, leave this value blank. Example: https://blobname.blob.core.windows.net/?sv=2020-08-04&ss=bfqt&srt=sco&sp=rwdlacupitfx&se=2023-12-10T16:46:02Z&st=2021-12-10T08:46:02Z&spr=https&sig=XXXX |
x |
|
Bucket Name |
Name of the bucket that contains the file. If you store the file in a sub-folder, enter the path in the following format: <bucket name>/<sub-folder>. Example: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name of your source or target file and its relative path from the bucket root. |
|
|
Options - Column Separator |
Character that delimits columns, if you use a column deliminator in your tables. |
x |
|
Options - Row Separator |
Character that delimits a row. The default value is \r\n. |
x |
|
Options - Skip Lines Starting With |
Rows which start with the specified value are excluded from tests. To define more than one value, enter a semicolon-separated list. |
x |
|
Options - Encoding |
File encoding format. Allowed values are Default, ASCII, Unicode, and UTF8. The Default format uses the encoding of your operating system. |
x |
If you want to integrate a different Cloud Service Provider on your Windows or Linux machine, you need to create your own rclone configuration. To do so, run the corresponding executable file:
-
rclone_x64_windows.exe config on Windows.
-
rclone_x64_linux config on Linux.
By default, when you install the Data Integrity Agent on Windows, this file is located at c:\Program Files\TRICENTIS\Tricentis Tosca Data Integrity Agent\Agent.
|
Value |
Description |
Optional |
|---|---|---|
|
Configuration Filename |
Name of the local rclone configuration file. |
|
|
Remote Name |
Name of the configuration section from the configuration file. |
|
|
Bucket Name |
Name of the bucket that contains the file. If you store the file in a sub-folder, enter the path in the following format: <bucket name>/<sub-folder>. Example: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name of your source or target file. |
|
|
Options - Column Separator |
Character that delimits columns, if you use a column deliminator in your tables. |
x |
|
Options - Row Separator |
Character that delimits a row. The default value is \r\n. |
x |
|
Options - Skip Lines Starting With |
Rows which start with the specified value are excluded from tests. To define more than one value, enter a semicolon-separated list. |
x |
|
Options - Encoding |
File encoding format. Allowed values are Default, ASCII, Unicode, and UTF8. The Default format uses the encoding of your operating system. |
x |
For more information about how to configure rclone, click here.
Tricentis Data Integrity supports Parquet files as your source or target.
Limitations
Working with Parquet files has the following limitations:
-
Parquet files are read in tabular format. Hierarchical structures are transformed into a table structure.
-
The supported compression codecs are GZIP, Snappy, and 'none'.
-
Skipping rows isn't supported.
Choose one of the following file types:
|
Value |
Description |
Optional |
|---|---|---|
|
Path |
Full path to an Avro file or a folder that contains multiple Avro files with the same schema. You can use wildcards *. If you use a folder or wildcard, Data Integrity orders the files by name and reads them first to last. Examples: C:\MyAvroFolder\Sample.avro C:\MyAvroFolder C:\MyAvroFolder\Samples*.avro |
|
|
Value |
Description |
Optional |
|---|---|---|
|
Access Key Id |
S3 access key ID. |
|
|
Bucket Name |
Name of the bucket that contains the file. If you store the file in a sub-folder, enter the path in the following format: <bucket name>/<sub-folder>. Example: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Full name of your source/target file. Use wildcards * to specify multiple files. |
|
|
Provider Name |
Name of your S3 provider. You can enter one of the following values:
|
|
|
Region |
The physical region where the file is stored. Examples: us-east-1: US Region, Northern Virginia, or Pacific Northwest eu-central-1 : EU (Frankfurt) Region ap-southeast-2: Asia Pacific (Sydney) Region |
|
|
Secret Access Key |
Secret access key. If you want to access the file anonymously, leave the value blank. |
x |
|
Value |
Description |
Optional |
|---|---|---|
|
Service Account Filepath |
Path to the JSON file that contains the service account credentials. |
|
|
Project Id |
Globally unique identifier of the project you want to access. |
|
|
Region |
The physical region where the file is stored. Examples: us-east-1: US Region, Northern Virginia, or Pacific Northwest eu-central-1 : EU (Frankfurt) Region ap-southeast-2: Asia Pacific (Sydney) Region |
|
|
Bucket Name |
Name of the bucket that contains the file. If you store the file in a sub-folder, enter the path in the following format: <bucket name>/<sub-folder>. Example: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name of your source or target file and its relative path from the bucket root. |
|
|
Value |
Description |
Optional |
|---|---|---|
|
Account |
Storage account name. |
|
|
Key |
Storage account key. |
|
|
SAS Url |
Account-level SAS URL or container level SAS URL. If you use Account and Key instead, leave this value blank. Example: https://blobname.blob.core.windows.net/?sv=2020-08-04&ss=bfqt&srt=sco&sp=rwdlacupitfx&se=2023-12-10T16:46:02Z&st=2021-12-10T08:46:02Z&spr=https&sig=XXXX |
x |
|
Bucket Name |
Name of the bucket that contains the file. If you store the file in a sub-folder, enter the path in the following format: <bucket name>/<sub-folder>. Example: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name of your source or target file and its relative path from the bucket root. |
|
If you want to integrate a different Cloud Service Provider on your Windows or Linux machine, you need to create your own rclone configuration. To do so, run the corresponding executable file:
-
rclone_x64_windows.exe config on Windows.
-
rclone_x64_linux config on Linux.
By default, when you install the Data Integrity Agent on Windows, this file is located at c:\Program Files\TRICENTIS\Tricentis Tosca Data Integrity Agent\Agent.
|
Value |
Description |
Optional |
|---|---|---|
|
Configuration Filename |
Name of the local rclone configuration file. |
|
|
Remote Name |
Name of the configuration section from the configuration file. |
|
|
Bucket Name |
Name of the bucket that contains the file. If you store the file in a sub-folder, enter the path in the following format: <bucket name>/<sub-folder>. Example: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name of your source or target file. |
|
For more information about how to configure rclone, click here.
Choose one of the following JSON file types:
|
Value |
Description |
Optional |
|---|---|---|
|
Filename |
Full file path and file name of your source or target file. |
|
|
JSONPaths Filename |
Full path to a file with JSONPaths. This allows Tosca to select column names and transformation logic. The JSONPaths file must be in the same bucket/directory as the data files or in a sub-bucket/directory. If the file is in a sub-bucket/directory, enter the relative path together with the file name. If you leave this value empty, Data Integrity uses a wildcard * as JSONPath. It unpacks hierarchical structures one level deep. Sample content for JSONPath: For Name, note the following:
|
x |
|
Value |
Description |
Optional |
|---|---|---|
|
Access Key Id |
S3 access key ID. |
|
|
Bucket Name |
Name of the bucket that contains the file. If you store the file in a sub-folder, enter the path in the following format: <bucket name>/<sub-folder>. Example: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Full name of your source/target file. Use wildcards * to specify multiple files. |
|
|
Provider Name |
Name of your S3 provider. You can enter one of the following values:
|
|
|
Region |
The physical region where the file is stored. Examples: us-east-1: US Region, Northern Virginia, or Pacific Northwest eu-central-1 : EU (Frankfurt) Region ap-southeast-2: Asia Pacific (Sydney) Region |
|
|
Secret Access Key |
Secret access key. If you want to access the file anonymously, leave the value blank. |
x |
|
JSONPaths Filename |
Full path to a file with JSONPaths. This allows Tosca to select column names and transformation logic. The JSONPaths file must be in the same bucket/directory as the data files or in a sub-bucket/directory. If the file is in a sub-bucket/directory, enter the relative path together with the file name. If you leave this value empty, Data Integrity uses a wildcard * as JSONPath. It unpacks hierarchical structures one level deep. Sample content for JSONPath: For Name, note the following:
|
x |
|
Value |
Description |
Optional |
|---|---|---|
|
Service Account Filepath |
Path to the JSON file that contains the service account credentials. |
|
|
Project Id |
Globally unique identifier of the project you want to access. |
|
|
Region |
The physical region where the file is stored. Examples: us-east-1: US Region, Northern Virginia, or Pacific Northwest eu-central-1 : EU (Frankfurt) Region ap-southeast-2: Asia Pacific (Sydney) Region |
|
|
Bucket Name |
Name of the bucket that contains the file. If you store the file in a sub-folder, enter the path in the following format: <bucket name>/<sub-folder>. Example: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name of your source or target file and its relative path from the bucket root. |
|
|
JSONPaths Filename |
Full path to a file with JSONPaths. This allows Tosca to select column names and transformation logic. The JSONPaths file must be in the same bucket/directory as the data files or in a sub-bucket/directory. If the file is in a sub-bucket/directory, enter the relative path together with the file name. If you leave this value empty, Data Integrity uses a wildcard * as JSONPath. It unpacks hierarchical structures one level deep. Sample content for JSONPath: For Name, note the following:
|
x |
|
Value |
Description |
Optional |
|---|---|---|
|
Account |
Storage account name. |
|
|
Key |
Storage account key. |
|
|
SAS Url |
Account-level SAS URL or container level SAS URL. If you use Account and Key instead, leave this value blank. Example: https://blobname.blob.core.windows.net/?sv=2020-08-04&ss=bfqt&srt=sco&sp=rwdlacupitfx&se=2023-12-10T16:46:02Z&st=2021-12-10T08:46:02Z&spr=https&sig=XXXX |
x |
|
Bucket Name |
Name of the bucket that contains the file. If you store the file in a sub-folder, enter the path in the following format: <bucket name>/<sub-folder>. Example: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name of your source or target file and its relative path from the bucket root. |
|
|
JSONPaths Filename |
Full path to a file with JSONPaths. This allows Tosca to select column names and transformation logic. The JSONPaths file must be in the same bucket/directory as the data files or in a sub-bucket/directory. If the file is in a sub-bucket/directory, enter the relative path together with the file name. If you leave this value empty, Data Integrity uses a wildcard * as JSONPath. It unpacks hierarchical structures one level deep. Sample content for JSONPath: For Name, note the following:
|
x |
If you want to integrate a different Cloud Service Provider on your Windows or Linux machine, you need to create your own rclone configuration. To do so, run the corresponding executable file:
-
rclone_x64_windows.exe config on Windows.
-
rclone_x64_linux config on Linux.
By default, when you install the Data Integrity Agent on Windows, this file is located at c:\Program Files\TRICENTIS\Tricentis Tosca Data Integrity Agent\Agent.
|
Value |
Description |
Optional |
|---|---|---|
|
Configuration Filename |
Name of the local rclone configuration file. |
|
|
Remote Name |
Name of the configuration section from the configuration file. |
|
|
Bucket Name |
Name of the bucket that contains the file. If you store the file in a sub-folder, enter the path in the following format: <bucket name>/<sub-folder>. Example: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name of your source or target file. |
|
|
JSONPaths Filename |
Full path to a file with JSONPaths. This allows Tosca to select column names and transformation logic. The JSONPaths file must be in the same bucket/directory as the data files or in a sub-bucket/directory. If the file is in a sub-bucket/directory, enter the relative path together with the file name. If you leave this value empty, Data Integrity uses a wildcard* as JSONPath. It unpacks hierarchical structures one level deep. Sample content for JSONPath: For Name, note the following:
|
x |
For more information about how to configure rclone, click here.
To use OLAP, fill out the following TestStepValues:
|
Value |
Description |
Optional |
|---|---|---|
|
SSAS |
Connect to SQL Server Analysis Services. |
|
|
SSAS - Connection string |
Connection string for SSAS. |
|
|
SSAS - Query |
Query to retrieve data to compare. |
|
|
SSAS - Options - Connect Timeout |
Time in seconds after which Tosca DI aborts an active connection. The default value is 30 seconds. |
X |
|
SSAS - Options - Command Timeout |
Time in seconds after which Tosca DI aborts an active command. The default value is 180 seconds. |
X |
Tricentis Data Integrity supports custom data sources. Click here for information on how to integrate your custom data source reader.
Once you have done so, fill out the following TestStepValues:
|
Value |
Description |
Optional |
|---|---|---|
|
Class Attribute Name |
In the Value field, enter the name of your custom data source reader. The name is declared in the ClassAttributeName of your data source interface. Example: CustomCSVReader |
|
|
Parameters - Key |
Specify the key-value pair to pass information to your custom implementation code:
Example: name FilePath, value D:\TestFile.csv If you work with COBOL files, you must use specific parameters (see chapter "Run tests with COBOL files"). |
|
|
|
In this example, you want to compare data from two CSV files. To do so, you use a custom CSV file reader (see our code sample). You perform the following steps:
Row by Row Comparison with custom data source reader You can now run your TestCase. |

Additional source and target configurations
There are additional parameters in the Source and Target TestStepValues that let you define how to handle rows, columns, and cells during the reconciliation test.
|
Value |
Description |
Optional |
|---|---|---|
|
Skip first #n rows |
Define the number of rows which should be ignored. Skipping starts at the top of the data source. |
X |
|
Value |
Description |
Optional |
|---|---|---|
|
1st Row Contains Column Names |
Specifies whether the first line of the data source contains the column names. The default value is True. |
X |
|
RemapColumn Names |
Remap the column names via file. Specify the full file path to a text or CSV file with the column mappings. The file has to start with the header row Current Column Name;Mapped Column Name followed by one line for each column that you want to rename. Example: Current Column Name;Mapped Column Name Name1;First Name Name2;Last Name |
X |
|
Remap Column Names - Current Name |
Remap the column names manually. In the Name column, specify the name of the column you want to rename. In the Value column, specify the new name. |
X |
|
Tosca uses this locale to determine the format of the numeric values, mainly decimal and thousand separators, of the columns that are defined in Tolerances. |
X |
Cell settings contains two options:
-
All Columns - Option applies an action all columns.
-
Single Columns - <Name> applies an action to a specified column. To specify a column, replace <Name> with the column name.
You can apply the following values:
|
Value |
Description |
|---|---|
|
Trim |
Removes all leading and trailing white space characters. Default scope: HeaderAndData |
|
Trim[<character>] |
Removes all leading and trailing occurrences of the specified character. Default scope: HeaderAndData Exchange <character> with the character you want to remove. To remove a ", enter the " four times, e.g. Trim[""""]. |
|
TrimStart |
Removes all leading white space characters. Default scope: HeaderAndData |
|
TrimStart[<character>] |
Removes all leading occurrences of the specified character. Default scope: HeaderAndData Exchange <character> with the character you want to remove. To remove a ", enter the " four times, e.g. TrimStart[""""]. |
|
TrimEnd |
Removes all trailing white-space characters. Default scope: HeaderAndData |
|
TrimEnd[<character>] |
Removes all trailing occurrences of the specified character. Default scope: HeaderAndData Exchange <character> with the character you want to remove. To remove a ", enter the " four times, e.g. TrimEnd[""""]. |
|
Replace[<string>][<string>] |
Replaces all occurrences of the first string with the second string. Default scope: Data |
|
ReplaceRegex [<search regex>][<replace string>] |
Replaces strings with regular expressions. You can replace special characters and unicode symbols, or use capture groups. If you want to use curly braces {}, you must escape them with double quotes "". Default scope: Data |
|
Substring[<start index>] |
Extracts a part of a longer string. The extract starts at the defined start index position and runs until the end of the string. Default scope: Data For example: Substring[9] with input Project Manager returns Manager. |
|
Substring[<start index>][<length>] |
Extracts a part of a longer string. The extract starts at the defined start index position and contains the number of characters specified in length. Default scope: Data For example: Substring[9][3] with input Project Manager returns Man. |
|
Right[<length>] |
Extracts a part of a longer string. The extract runs from the end of the string towards the beginning and contains the number of characters specified in length. Default scope: Data For example: Right[7] with input Project Manager returns Manager. |
|
Lowercase |
Converts the string to lowercase using the currently active locale. Default scope: Data For example: Lowercase with input Project Manager returns project manager. |
|
Lowercase[Culture:<culture name>] |
Converts the string to all lowercase. Lowercase[Culture:<culture name>] uses the given culture name to create a new locale. Default scope: Data For example: Lowercase[Culture:zh-Hans] uses the culture information of "Chinese(simplified)" to convert uppercase to lowercase characters. |
|
Uppercase |
Converts the string to uppercase using the currently active locale. Default scope: Data For example: Uppercase with input Project Manager returns PROJECT MANAGER. |
|
Uppercase[Culture:<culture name>] |
Converts the string to all uppercase. Uppercase[Culture:<culture name>] uses the given culture name to create a new locale. Default scope: Data For example: Lowercase[Culture:en-us] uses the culture information of "English - United States" to convert lowercase to uppercase characters. |
|
Trim double quotes |
Removes leading and trailing double quotes. For example: Trim double quotes with input """Project Manager""" returns Project Manager. |
To change the default scope of an action, add a Scope parameter:
-
To apply the action to the header row only, add the parameter [Scope:Header].
-
To apply the action to all data rows but not the header, add the parameter [Scope:Data].
-
To apply the action to the header and all data rows, add the parameter [Scope:HeaderAndData].
|
|
This example illustrates how to replace all instances of the string CustomerDataAustria with the string CustomerDataUSA. Apply this change to the header and all data rows. To do so, define the following action: Replace[<CustomerDataAustria>][<CustomerDataUSA>][Scope:HeaderAndData] |
Define your Row Key
The Row by Row Comparison algorithm uses the Row Key as a unique identifier to compare rows.
|
Value |
Description |
|---|---|
|
Row Key |
Specify the Row Key in one of the following ways:
The column name(s) that you specify in the Row Key must be exactly the same as in the table. This includes capitalization and blank spaces. |
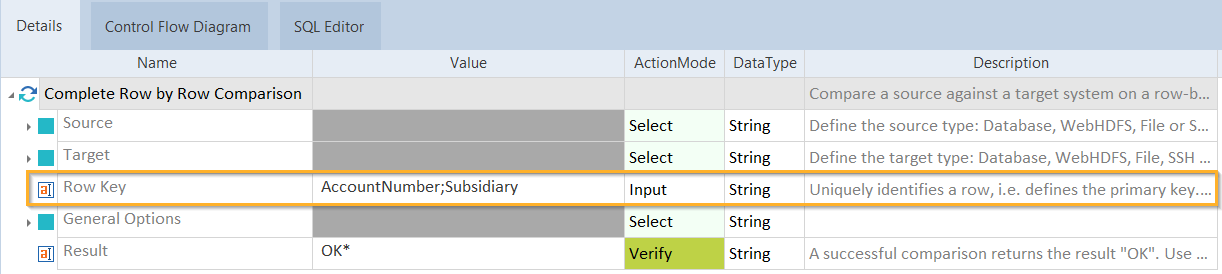
Row Key with two column names
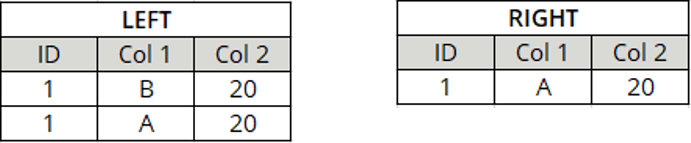
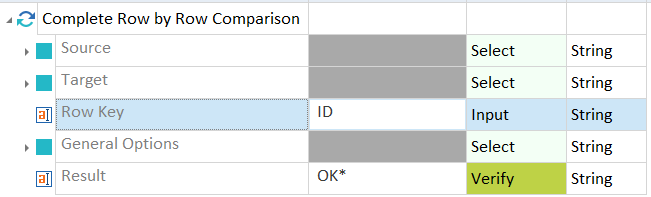

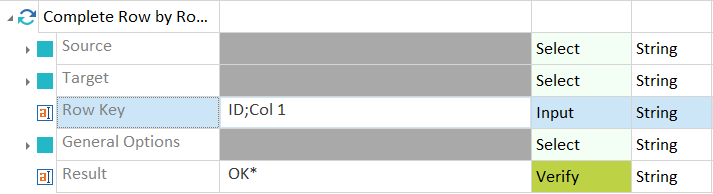

Define general options
Populate the General Options TestStepValues to define general test parameters.
You can use the following TestStepValues:
|
Value |
Description |
Optional |
|---|---|---|
|
Max Errors |
Specify the maximum number of errors before Data Integrity cancels the execution. The default value is 100. |
X |
|
Columns to Exclude |
Semicolon-separated list of columns to exclude from comparison. |
X |
|
Case Sensitive Column Names |
If set to True, column matching from source to target is case-sensitive. For example: ID is not the same as id. |
X |
|
Skip Rowcount |
By default, Data Integrity performs a row count before it calculates how long the comparison will take. You can skip the row count to save time. To do so, set this attribute to True. Default value: False |
X |
|
Allows the comparison of an empty source and/or target without throwing an error. This means that the test runs through and creates a report. This is useful if you expect the source or target to be empty and the test should pass. To do so, set this attribute to True. Default value: False Note: consider whether you want to Export Unmatched Target Rows or not. See the tables below for more information. |
X |
The table below shows how the comparison of an empty data source, if you set Allow Empty Comparison to True.
|
Source |
Target |
Export Unmatched Target Rows |
Expected test result |
|---|---|---|---|
|
Empty |
Empty |
True |
Pass: test runs through. |
|
Empty |
Empty |
False |
Pass: test runs through. |
|
Empty |
NOT Empty |
True |
Fail: test runs through, shows differences. |
|
Empty |
NOT Empty |
False |
Pass: test runs through, shows that no differences were found. |
|
NOT Empty |
Empty |
True |
Fail: test runs through, shows differences. |
|
NOT Empty |
Empty |
False |
Fail: test runs through, shows differences. |
The table below shows how the comparison of an empty data source works, if you set Allow Empty Comparison to False.
|
Source |
Target |
Export Unmatched Target Rows |
Expected test result |
|---|---|---|---|
|
Empty |
Empty |
True |
Throws an error, doesn't create a report. |
|
Empty |
Empty |
False |
Throws an error, doesn't create a report. |
|
Empty |
NOT Empty |
True |
Fail: test runs through, shows differences. |
|
Empty |
NOT Empty |
False |
Throws an error, doesn't create a report. |
|
NOT Empty |
Empty |
True |
Fail: test runs through, shows differences. |
|
NOT Empty |
Empty |
False |
Fail: test runs through, shows differences. |
Comparison reports allow you to save detailed reports. Tosca saves the data to a local database file that you can view with the Data IntegrityReport Viewer.
|
Value |
Description |
Optional |
|---|---|---|
|
Report Path |
Specify the full path and file name for your comparison report or only a file path. If you provide only a file path, Data Integrity generates a default file name in the following format: TestResultReport_yyyyMMdd-HHmmss. For example, if you specify the file path C:\temp or C:\temp\, Data Integrity generates the report file C:\temp\TestResultReport_yyyyMMdd-HHmmss. |
X |
|
Export Unmatched Target Rows |
Select one of the following export options:
If your target contains many unmatched rows, this might affect performance because all rows have to be exported. |
X |
|
Export Matched Data |
Select one of the following export options:
Tricentis doesn't recommend logging all matched data because it has a negative effect on performance. |
X |
The goal of Row by Row Comparison is to confirm that the data of source row and target row match. If the rows don't match on all columns, Tricentis Data Integrity considers them a mismatch.
You can, however, use tolerances to define which difference between compared values is acceptable. This allows Data Integrity to still consider source and target value a match even if there is a slight difference between them.
Click here for more information on tolerances.
|
Value |
Description |
|---|---|
|
Tolerances |
Enter one of the following values:
If you use two values to indicate a tolerance range, separate them with a semi-colon. Example value: -5;+5 |
Verify the result
The TestStepValue Result allows you to verify the outcome of the comparison. To do so, enter one of following values into the Value column:
-
To verify against a successful comparison, enter the value OK.
-
To verify against an expected result, use the result text from the Loginfo once you have executed your TestCase and customized it.

Verify against an expected result